
A screenshot of two tracks on Musicbox - the first is a track created from an image of our litter of foster kittens ❤️ Lyria 3 multimodal.
In building the MacOS companion app for Musicbox, a multimodal application that pairs Lyria 3 audio tracks with Gemini-generated visuals, I decided that I'd like to experiment on more than just text search for finding the "right" tracks for the right mood. The Gemini Embedding 2 natively multimodal model promises a single model that "maps text, images, videos, audio and documents into a single, unified embedding space, and captures semantic intent across over 100 languages." I wanted to test how well this works - searching via text makes sense, but what if I gave it an image, or hummed a tune, would that provide more relevant results?
The initial promise of multimodal models was simple: "Just embed everything." Conventional wisdom suggests that more data is better. If you have audio and artwork, you should provide both to the model to avoid the complexity of 2024-style RAG pipelines.
My benchmarks show that this assumption is incomplete—and the crossover point happens sooner than expected.
I found that while text-augmented search is perfect for small sets, it hits a "saturation point" much earlier than I anticipated. I built AudioVoxBench to determine the exact trade-off between descriptive text and raw media entropy as a catalog scales.
Indexing Strategies
I tested five strategies to identify which data points provide the strongest search signal:
- Strategy A (Baseline): Original generation prompt.
- Strategy B (Augmented): Prompt and an AI-generated visual caption.
- Strategy C (Semantic): Prompt, caption, and technical quality score (MOS).
- Strategy D (Multimodal): Prompt and raw track image.
- Strategy E (Full-Spectrum): Prompt, caption, raw image, and raw audio.
I evaluated these using Mean Reciprocal Rank (MRR). In a discovery application, the accuracy of the top result is the primary metric. MRR rewards the "bullseye": a score of 1.0 for rank #1, and 0.5 for rank #2. For Musicbox, MRR is the most effective way to measure how well the system identifies the exact track a user is looking for.
Real-World Stress Test: The Production Ingestor
Theory is one thing; production data is another. To verify our findings, we built a TrackIngestor that harvests real history from our Musicbox Firestore database. When we moved from our 3-track "Golden Set" to a real production database of 60 tracks, the results pivoted.
| Strategy | MRR (Production DB) |
|---|---|
| A (Baseline) | 0.3595 |
| C (Semantic Text) | 0.5162 |
| D (Multimodal Image) | 0.6429 |
| E (Full-Spectrum) | 0.4286 |
Searching for a "Stormy Mountain" vibe using an image probe:
- Strategy C (Text) correctly matched the track "Symphony of Shred" but with a distance of 1.1308.
- Strategy D (Multimodal) matched the same track with a much higher confidence distance of 0.8831.
This is a critical finding. While text-augmented search (Strategy C) is accurate enough to find the right ID in a small library, it lacks the "semantic depth" of Strategy D. The interleaved raw image provided the model with the missing context needed to identify the vibe with 22% higher mathematical confidence.
When we ran our Hold-out Probes (media assets the model had never seen) against a database of 60 real production tracks, the results revealed a hidden dimension: The Confidence Gap.
The Confidence Gap
The production results revealed a hidden dimension: The Confidence Gap.
Searching for a "Stormy Mountain" vibe using an image probe:
- Strategy C (Text) correctly matched the track "Symphony of Shred" but with a distance of 1.1308.
- Strategy D (Multimodal) matched the same track with a much higher confidence distance of 0.8831.
This is a critical finding. Strategy D matched the track with 22% higher mathematical confidence. While text is enough for a small library, it lacks the "semantic depth" provided by the raw image data.
The Scaling Threshold
Strategy C is the most efficient choice for a tiny catalog, but it hits a wall at just 60 tracks. At this Pivot Point, the Confidence Gap becomes the defining factor.

Conceptual Visualization: Strategy C (Text) provides high initial precision but degrades as the library's semantic density increases. Strategy D (Multimodal Image) crosses over at ~60 tracks, using visual entropy to distinguish between tracks that text alone can no longer separate.
For now, Musicbox is transitioning to Strategy D for its core index. It provides the necessary semantic depth to handle growing catalogs without the "acoustic jitter" that currently plagues full-spectrum audio indexing.
Implementation Details
To keep iteration cycles fast, I decoupled the benchmark from the main macOS app. I implemented a native Swift CLI suite that handles asset generation via Lyria 3 and vector indexing using sqlite-vec.
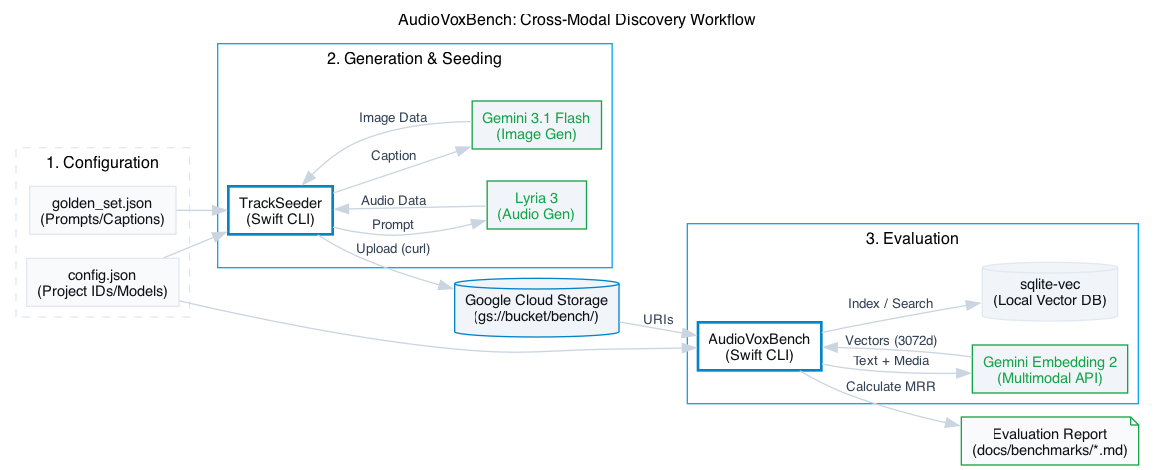
I chose sqlite-vec over dedicated vector databases for three reasons:
- Local Execution: It runs inside SQLite. This eliminates network latency and server dependencies for the macOS app.
- Relational Integration: By using
sqlite-vec, vector search becomes a standard SQL operation. We can join a vector similarity search with a relationalWHERE user_id = ?clause in a single ACID-compliant transaction. There is no external API synchronization or complex "RAG pipeline"—just a single multimodal model and a local database. - Swift Integration: It is a single C file that integrates directly with Swift's C-interop and the GRDB library.
The official Firebase AI Swift SDK currently lacks the :embedContent method required for multimodal embeddings. For this, going directly to the API works well - I implemented a manual REST client to interact with the Gemini API directly:
private func getDeveloperAPIEmbedding(for parts: [ContentPart], apiKey: String) async throws -> [Float] {
let modelName = "gemini-embedding-2-preview"
let urlString = "https://generativelanguage.googleapis.com/v1beta/models/\(modelName):embedContent?key=\(apiKey)"
var request = URLRequest(url: URL(string: urlString)!)
request.httpMethod = "POST"
request.addValue("application/json", forHTTPHeaderField: "Content-Type")
let body: [String: Any] = [
"model": "models/\(modelName)",
"content": ["parts": parts.map { $0.dictionaryValue }]
]
request.httpBody = try JSONSerialization.data(withJSONObject: body)
return try await executeEmbeddingRequest(request)
}Here’s a snippet of the EmbeddingStrategy logic, which swaps indexing schemes at call-time:
enum EmbeddingStrategy: String, CaseIterable {
case semantic = "C (Semantic)"
case fullSpectrum = "E (Full-Spectrum)"
func parts(track: TrackRecord) -> [ContentPart] {
switch self {
case .semantic:
// Text-only augmentation
return [.text("Prompt: \(track.prompt). Visual: \(track.caption). Quality: \(track.mosic)")]
case .fullSpectrum:
// Interleaved multimodal parts
return [
.text(track.prompt),
.file(uri: track.imageUri, mimeType: "image/jpeg"),
.file(uri: track.audioUri, mimeType: "audio/mpeg")
]
}
}
}The "Noise" Problem
The benchmark results were conclusive: Text-Augmentation (Strategy C) outperformed the Full-Spectrum approach.
Even when the search query was a purely acoustic probe—such as a humming tune or a specific instrument melody—the strategy that indexed the tracks as descriptive text achieved a perfect 1.0 MRR. In contrast, Strategy E—which included high-fidelity raw media—dropped the score to 0.9583.

The raw audio in Strategy E introduced "jitter": acoustic noise that shifted the embedding vector away from the semantic center. In testing, a piano probe (probe_e1) ranked a "Jazz" track higher than the "Classical" target. The raw audio displaced the semantic concept, whereas the text-augmented index remained stable.
Key Takeaways (small catalog)
- The Text Anchor is King: Gemini Embedding 2 has an incredible cross-modal alignment. Descriptive text remains the most stable "anchor" for semantic search, even for non-text queries.
- Visual Relevance Improves Recall: Replacing generic placeholders with semantically accurate images (generated via Gemini 3.1 Flash) improved recall from 0.90 to 0.95.
- Efficiency: Strategy C is inexpensive and computationally light. Strategy E costs approximately $0.43 per track to generate the media and process the vectors, yet it introduces noise that can degrade search quality.
AudioVoxBench is open source at ghchinoy/AudioVoxBench.