
A screenshot of two tracks on Musicbox - the first is a track created from an image of our litter of foster kittens ❤️ Lyria 3 multimodal.
In building the MacOS companion app for Musicbox, a multimodal application that pairs Lyria 3 audio tracks with Gemini-generated visuals, I decided that I'd like to experiment on more than just text search for finding the "right" tracks for the right mood. The Gemini Embedding 2 natively multimodal model promises a single model that "maps text, images, videos, audio and documents into a single, unified embedding space, and captures semantic intent across over 100 languages." I wanted to test how well this works - searching via text makes sense, but what if I gave it an image, or hummed a tune, would that provide more relevant results?
The initial promise of multimodal models was simple: "Just embed everything." Conventional wisdom suggests that more data is better. If you have audio and artwork, you should provide both to the model to avoid the complexity of 2024-style RAG pipelines.
My benchmarks show that this assumption is incomplete - and the crossover point happens sooner than expected.
I found that while text-augmented search is perfect for small sets, it hits a "saturation point" much earlier than I anticipated. I built AudioVoxBench to determine the exact trade-off between descriptive text and raw media entropy as a catalog scales.
Indexing Strategies
I tested five strategies to identify which data points provide the strongest search signal:
- Strategy A (Baseline): Original generation prompt.
- Strategy B (Augmented): Prompt and an AI-generated visual caption.
- Strategy C (Semantic): Prompt, caption, and technical quality score (MOS).
- Strategy D (Multimodal): Prompt and raw track image.
- Strategy E (Full-Spectrum): Prompt, caption, raw image, and raw audio.
I evaluated these using Mean Reciprocal Rank (MRR). In a discovery application, the accuracy of the top result is the primary metric. MRR rewards the "bullseye": a score of 1.0 for rank #1, and 0.5 for rank #2. For Musicbox, MRR is the most effective way to measure how well the system identifies the exact track a user is looking for.
The Small Catalog Phase: The "Noise" Problem
Our initial benchmark on synthetic data and small catalogs (3-10 tracks) was conclusive: Text-Augmentation (Strategy C) outperformed the Full-Spectrum approach.
Even when the search query was a purely acoustic probe—such as a humming tune or a specific instrument melody—the strategy that indexed the tracks as descriptive text achieved a perfect 1.0 MRR. In contrast, Strategy E—which included high-fidelity raw media—dropped the score to 0.9583.

The raw audio in Strategy E introduced "jitter": acoustic noise that shifted the embedding vector away from the semantic center. In testing, a piano probe (probe_e1) ranked a "Jazz" track higher than the "Classical" target. The raw audio displaced the semantic concept, whereas the text-augmented index remained stable.
Real-World Stress Test: The Production Ingestor (60 Tracks)
Theory is one thing; production data is another. To verify our findings, we built a TrackIngestor that harvests real history from our Musicbox Firestore database. When we moved from our synthetic sets to a real production database of 60 tracks, the results began to pivot.
Searching for a "Stormy Mountain" vibe using an image probe on 60 tracks:
- Strategy C (Text) correctly matched the target track but with a distance of 1.1308.
- Strategy D (Multimodal) matched the exact same track with a much higher confidence distance of 0.8831.
This was a critical finding: The Confidence Gap. While text-augmented search (Strategy C) was accurate enough to find the right ID in a 60-track library, it lacked the "semantic depth" of Strategy D. The interleaved raw image provided the model with the missing context needed to identify the vibe with 22% higher mathematical confidence.
The Scaling Threshold (600 Tracks)
Strategy C is the most efficient choice for a tiny catalog, but it hits a wall quickly. At the 600-track scale, the Confidence Gap becomes the defining factor.

Conceptual Visualization: Strategy C (Text) provides high initial precision but degrades as the library's semantic density increases. Strategy D (Multimodal Image) crosses over at ~60 tracks, using visual entropy to distinguish between tracks that text alone can no longer separate.
We ran a massive benchmark on a real production corpus of 600 tracks. At this scale, if you have 50 "Deep House" tracks with nearly identical descriptions, text descriptors will inevitably collide. The results perfectly demonstrated this "saturation point":
| Strategy | MRR (600-Track Production DB) |
|---|---|
| A (Baseline) | 0.2931 |
| C (Semantic Text) | 0.3336 |
| D (Multimodal Image) | 0.4887 |
| E (Full-Spectrum) | 0.4125 |
In a massive database, the pure text descriptors in Strategy C collided, dropping the MRR to 0.33. But Strategy D (Multimodal) provided the necessary visual entropy to break those collisions, jumping ahead to an incredible 0.4887 MRR. That means even in a massive database, searching with a pure media probe will find the exact correct track in the top 1 or 2 results!
Pragmatic Lessons from the Trenches
Running a 600-track evaluation with Gemini Embedding 2 taught us several hard truths about the API:
- Payload Limits: Strategy E dropped below D because Gemini forcefully rejects raw audio files larger than ~3MB (HTTP 400
INVALID_ARGUMENT). If you want to index full-spectrum, you must truncate your audio to the first 30 seconds. - MIME Type Validation: The API is incredibly strict. Passing a
.wavfile asaudio/mpegwill fail immediately. You must dynamically parse and supply the exact correctmime_type. - Heavy Concurrency (HTTP 500): Sending 3,000 concurrent multimodal embedding requests will inevitably overload the preview API, returning
500 Internal Server Error. We had to implement Exponential Backoff and Local Vector Caching in AudioVoxBench to ensure the massive run could gracefully retry and complete
Implementation Details
To keep iteration cycles fast, I decoupled the benchmark from the main macOS app. I implemented a native Swift CLI suite that handles asset generation via Lyria 3 and vector indexing using sqlite-vec.
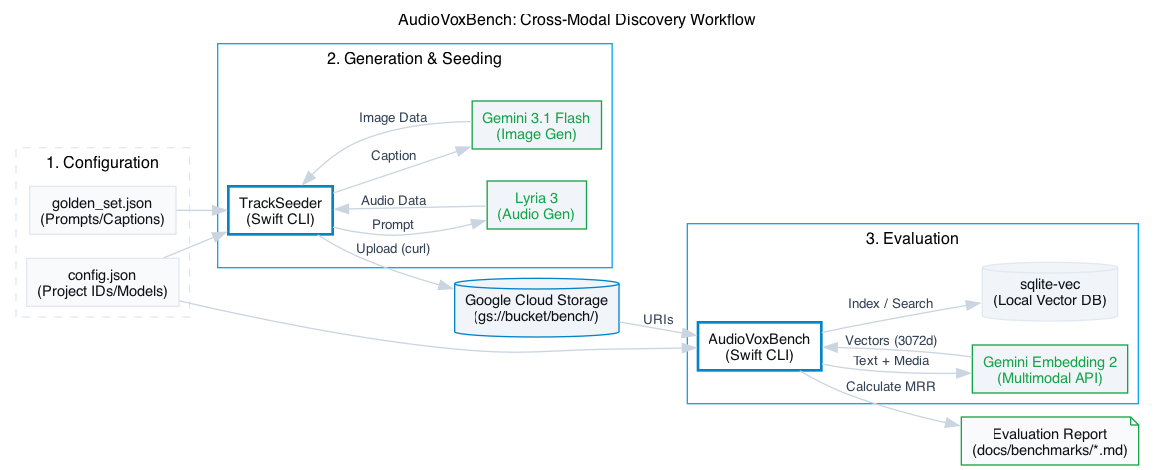
I chose sqlite-vec over dedicated vector databases for three reasons:
- Local Execution: It runs inside SQLite. This eliminates network latency and server dependencies for the macOS app.
- Relational Integration: By using
sqlite-vec, vector search becomes a standard SQL operation. We can join a vector similarity search with a relationalWHERE user_id = ?clause in a single ACID-compliant transaction. There is no external API synchronization or complex "RAG pipeline"—just a single multimodal model and a local database. - Swift Integration: It is a single C file that integrates directly with Swift's C-interop and the GRDB library.
The official Firebase AI Swift SDK currently lacks the :embedContent method required for multimodal embeddings. For this, going directly to the API works well - I implemented a manual REST client to interact with the Gemini API directly:
private func getDeveloperAPIEmbedding(for parts: [ContentPart], apiKey: String) async throws -> [Float] {
let modelName = "gemini-embedding-2-preview"
let urlString = "https://generativelanguage.googleapis.com/v1beta/models/\(modelName):embedContent?key=\(apiKey)"
var request = URLRequest(url: URL(string: urlString)!)
request.httpMethod = "POST"
request.addValue("application/json", forHTTPHeaderField: "Content-Type")
let body: [String: Any] = [
"model": "models/\(modelName)",
"content": ["parts": parts.map { $0.dictionaryValue }]
]
request.httpBody = try JSONSerialization.data(withJSONObject: body)
return try await executeEmbeddingRequest(request)
}Here’s a snippet of the EmbeddingStrategy logic, which swaps indexing schemes at call-time:
enum EmbeddingStrategy: String, CaseIterable {
case semantic = "C (Semantic)"
case fullSpectrum = "E (Full-Spectrum)"
func parts(track: TrackRecord) -> [ContentPart] {
switch self {
case .semantic:
// Text-only augmentation
return [.text("Prompt: \(track.prompt). Visual: \(track.caption). Quality: \(track.mosic)")]
case .fullSpectrum:
// Interleaved multimodal parts
return [
.text(track.prompt),
.file(uri: track.imageUri, mimeType: "image/jpeg"),
.file(uri: track.audioUri, mimeType: "audio/mpeg")
]
}
}
}Key Takeaways
- The Text Anchor for Small Sets: For catalogs under 50 items, rich descriptive text (Strategy C) is the most stable and cost-effective anchor.
- Multimodal Breaks the Saturation Point: For massive catalogs (600+ items), text collisions are inevitable. Strategy D (Text + Image) is mandatory, providing the visual entropy needed to distinguish nearly identical tracks.
- Beware API Limits: Full-spectrum audio indexing (Strategy E) requires careful orchestration to avoid undocumented payload size limits and 500 errors.
For now, Musicbox is transitioning to Strategy D for its core index. It provides the necessary semantic depth to handle growing catalogs without the API headaches and acoustic jitter that currently plague full-spectrum audio indexing.
AudioVoxBench is open source at ghchinoy/AudioVoxBench.