Intro: The Dream of the "Pocket Universe"
In 2023, DeepMind researchers (Vezhnevets et al.) introduced Concordia arXiv:2507.08892, arXiv:2312.03664, a library that moved us away from simple "Chatbots" and toward Generative Agent-Based Modeling (GABM).
The core research contention was simple but profound: agents shouldn't just talk to each other; they need to be grounded. By using a Game Master (GM) as a mediator, researchers could ensure that an agent's actions were physically, socially, and logically plausible. Whether simulating a snowed-in pub or a complex political election, the GM acted as the arbiter of reality.
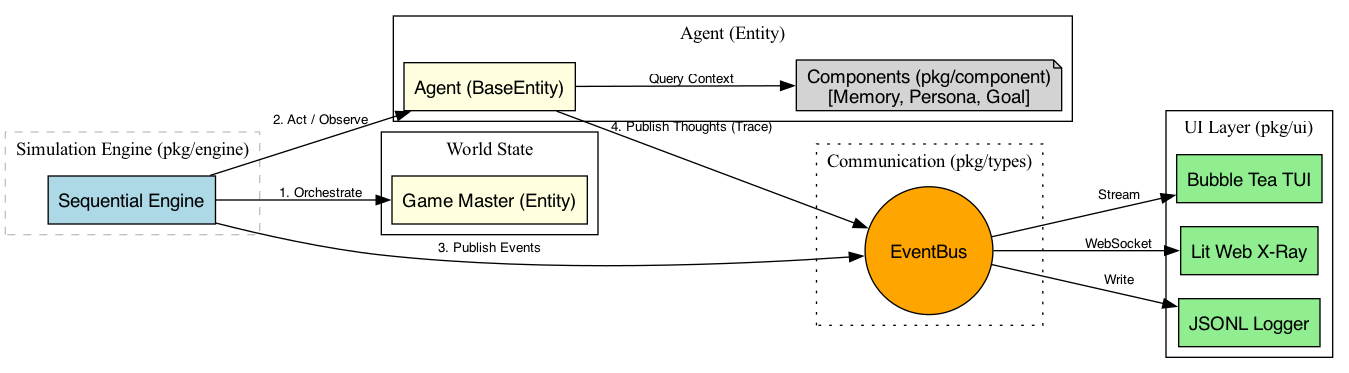
But as the research evolved from the Evaluationist (benchmarking AI) to the Simulationist (modeling real-world social phenomena), a major bottleneck emerged: the "Limit of Detail." As simulations grew to hundreds of agents with years of formative memories, the sequential, Python-based loops reached their performance ceiling.
Pandemonium is our answer: a high-performance Go implementation of Concordia designed to shatter that limit and enable the massive-scale, distributed agent networks of 2026.
The Research Foundation: Why It Matters
Concordia isn't just about fun narratives; it’s about solving critical AI safety and social alignment problems. Our Go implementation doubles down on three core research pillars:
A. The "Society of Mind" (Modularity)
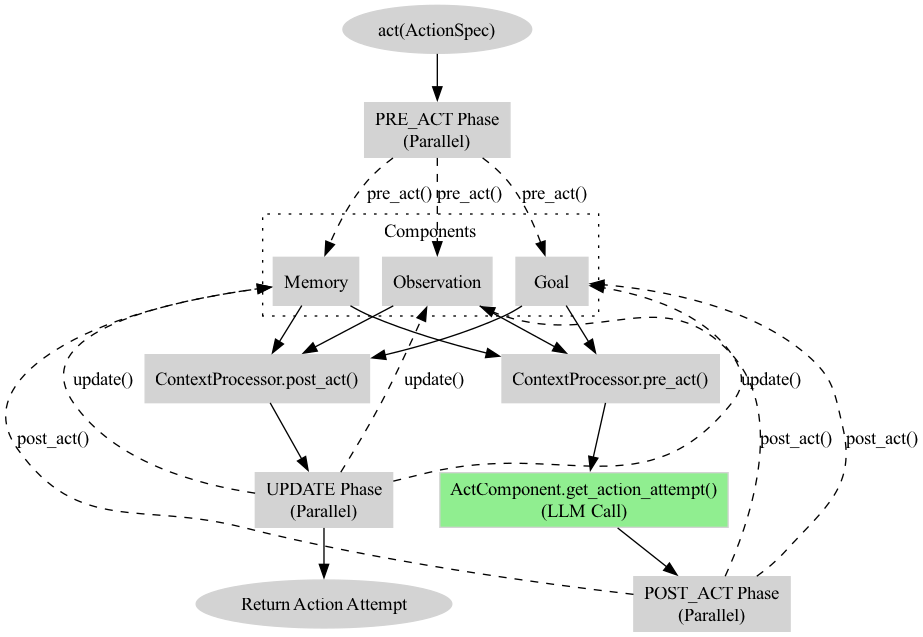
Following Minsky’s (1988) philosophy, Pandemonium treats an agent's mind as a set of interacting components. When an agent acts, they don't just "reply." They concurrently retrieve memories, check their goals, and perceive their situation—all before speaking. In Go, these cognitive phases happen in parallel goroutines, allowing for a level of cognitive complexity that was previously too slow to simulate.
B. Grounding as Safety
The GM isn't just a narrator; it’s a grounding mechanism. It prevents agents from "hallucinating" their way out of constraints. By moving to Go, I've added Strict Typing to the world state, making the arbiter of reality even more robust and predictable.
C. Evaluation vs. Realism
Researchers identify three perspectives for these systems:
- Evaluationist: Benchmarking capabilities in fair environments.
- Dramatist: Generating coherent, compelling narratives.
- Simulationist: Modeling high-fidelity social phenomena.
Pandemonium is built to support all three by allowing you to hot-swap engines and components.
Why Go?
Python is still quite useful. I chose Go for four reasons:
- Native Concurrency: Retrieving 10,000 memories shouldn't block perceiving the immediate scene. Go's goroutines make "Internal Monologues" lightning fast.
- An Update to the A2A Era: In 2026, agents aren't just local objects. They are standalone microservices. Pandemonium is built to support the A2A (Agent-to-Agent) protocol. And I just recently wrote an intro to using A2A for long running tasks with a neat little set of information ready for Gemini CLI to help out with.
- Deployment for Agents: A single statically linked binary with embedded scenarios is easier to deploy to supercomputers or edge devices than a Python environment with complex C-dependencies. Distributed agents will are easier to deploy, especially for where we're going next.
- Bard taught me Python: There're lots of great reasons for python, but I can't read all of them. Yes lots of the porting and code is done in conjunction with Gemini CLI, but I personally, the human, can't spot check, correct, or even suggest interesting changes in code if I can't read it.
The Deep Dive: Distributed Intelligence with A2A
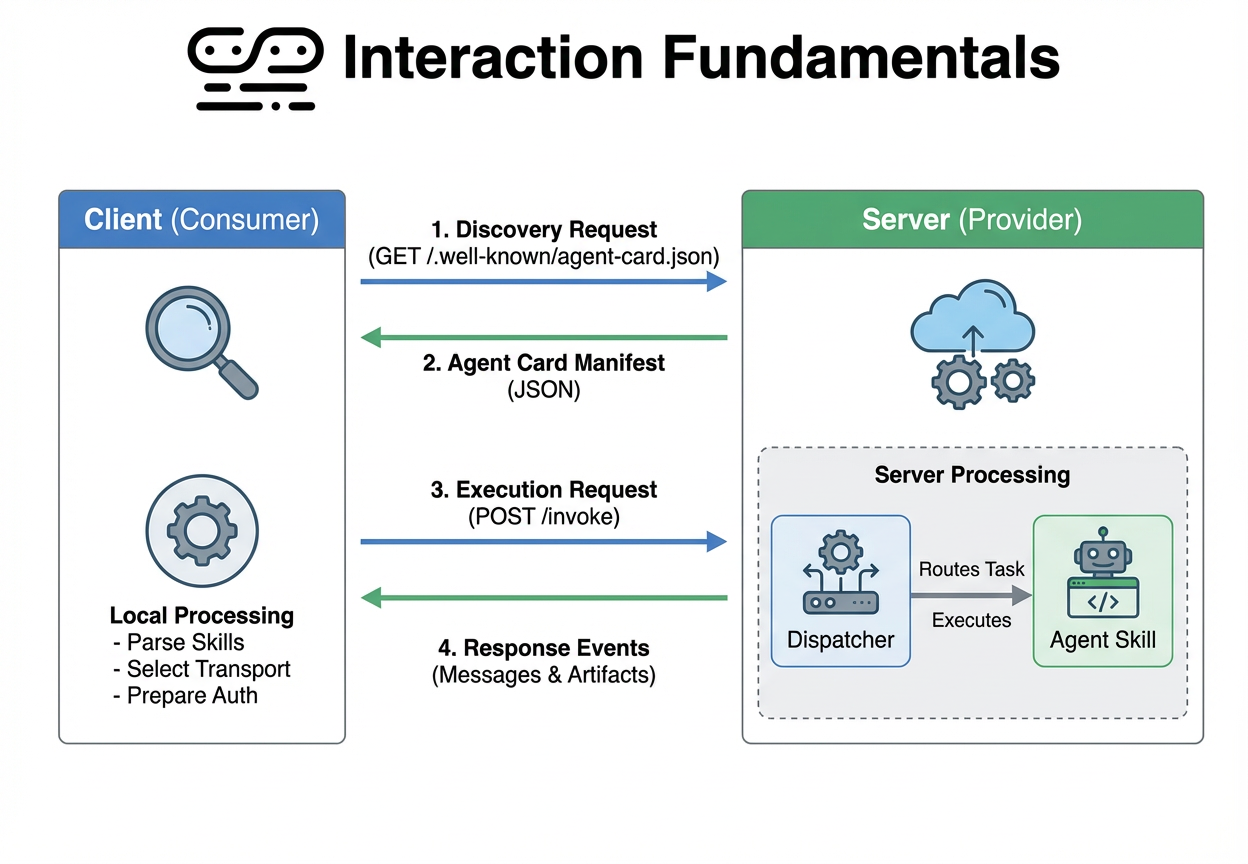
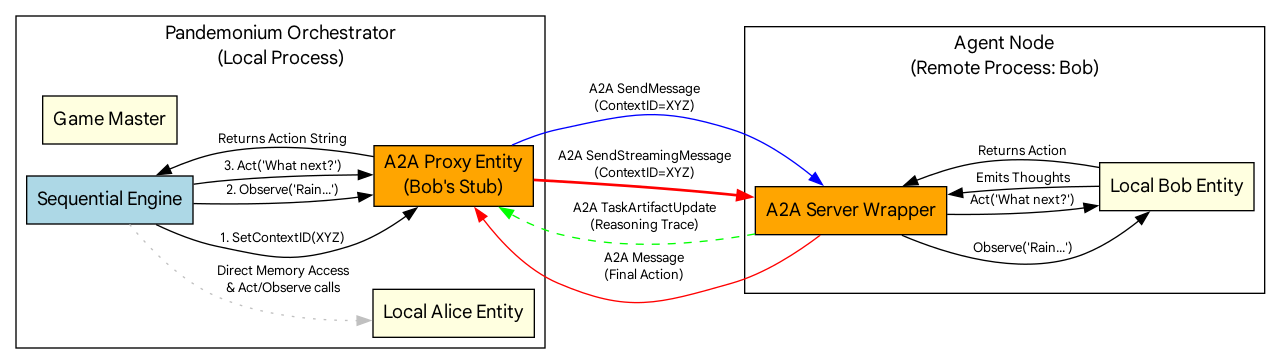
The most significant departure from the original research is our support for the A2A protocol. This transforms Pandemonium from a local library into a distributed network coordinator.
Self-Discovery via Agent Cards
Traditional simulations require you to hardcode every agent's capabilities. In Pandemonium, a remote agent describes itself via an Agent Card. This JSON manifest serves as the agent's "resume," listing its name, skills, and reasoning patterns.
For more, see Designing A2A services for long running agent services
Stateful Tasks & Artifacts
Unlike standard REST APIs, A2A interactions are stateful Tasks. When our GM asks a remote agent to act, it receives "Working" heartbeats and Artifacts—structured data packages containing the agent's internal monologue. This allows our X-Ray UI to pull reasoning traces from across the network.
What's Next?
Pandemonium's a great MVP and proves that I can run a small environment with distributed agents on one machine, but the vision is a bit bigger than that.
Imagine a time-limited scenario where you can provide an agent to do things on your behalf to achieve or collaborate on achieving a goal? Sound like a game? Sound like a Kaggle competition? What about if you have a hypothesis and want to have a bunch of agents debate over it?
Now that there's a base, we can plug in different types of memory, different types of constraint enforcement systems (turn by turn, open ended, etc.), and really start adjusting the levers of a byo agent simulation environment.
Some of the technical needs that are next are:
- Generative Reflection: Agents that periodically summarize their lives to form "long-term wisdom."
- Pandemonium Platform: A multi-tenant server that can run thousands of simulations simultaneously.
- Cloud-Native Memory: Integrating Vertex AI Vector Search for agents that remember interactions across years of simulated time.
Conclusion
Pandemonium is more than a port, it's adapting and extending lessons learned from Google DeepMind’s Concordia into a platform for the next generation of social simulation. By combining the research depth of Concordia with the performance of Go and the interoperability of A2A, we are building the foundation for truly autonomous digital societies.
Ready to join the simulation?
Check out our Project Primer or dive into the Go Adaptation Guide.